Choosing between RAG and fine‑tuning is a critical architectural decision when building enterprise AI systems for production. Both approaches solve different problems. Picking the wrong one can increase cost, risk, and long‑term maintenance effort.
Retrieval‑Augmented Generation (RAG) is best when your AI system needs access to constantly changing, proprietary data without retraining the model. Fine‑tuning is better when you need consistent behaviour, structured output, or domain‑specific language embedded directly into the model.
For most enterprise AI systems, the real challenge is not accuracy alone. It is scalability, governance, security, and operational cost at scale.
This article explains how RAG and fine‑tuning work in enterprise AI systems, where each approach fits best, and how to choose the right option for production‑ready deployments.
How to Decide Between RAG and Fine‑Tuning for Enterprise AI Systems
In enterprise environments, the choice between RAG and fine‑tuning depends on what your AI system must learn versus what it must look up. RAG excels when accuracy depends on fresh, traceable data such as internal documents, policies, or product knowledge. Fine‑tuning works best when the goal is to standardise behaviour, improve reasoning patterns, or enforce consistent output across use cases. Most production failures happen when teams fine‑tune models to store knowledge or use RAG to control behaviour. Understanding this distinction early helps enterprise AI teams avoid rework, reduce operational risk, and design systems that scale reliably from day one.
What Is RAG (Retrieval-Augmented Generation)?
RAG (Retrieval-Augmented Generation) is an AI architecture that allows language models to retrieve relevant information from external data sources before generating a response. Instead of relying only on what the model learned during training, RAG enables AI systems to “look up” current and business-specific information in real time.
For enterprises, this means you can build AI systems that are:
- More accurate
- More context-aware
- Easier to update
- Less prone to hallucinations
- Better aligned with proprietary business knowledge
Rather than retraining an expensive model every time your data changes, RAG lets your AI access the latest information instantly.
Retrieval-Augmented Generation is a framework that combines two core capabilities:
- Information Retrieval
- Natural Language Generation
In simple terms, your AI system first searches for relevant information from an external knowledge base and then uses that information to generate a more accurate response.
Think of it like giving your AI an open-book exam instead of forcing it to rely purely on memory.
RAG is best suited for enterprise AI systems that:
- Rely on frequently changing or proprietary data
- Must provide traceable and auditable responses
- Need to integrate with internal documents, databases, or knowledge bases
- Must scale across multiple use cases without repeated model updates
This retrieval-first approach dramatically improves enterprise AI reliability.
What Is Fine-Tuning?
Fine-tuning is the process of taking a pre-trained large language model (LLM) and training it further on your proprietary or task-specific data. Instead of building a model from scratch, you refine an existing foundation model, so it performs better for your specific enterprise use cases.
In simple terms, a fine-tuned model doesn’t “look up” information every time. Instead, it internalizes patterns, language structures, and domain-specific behaviors during training.
For enterprises, this can dramatically improve:
- Response quality
- Domain expertise
- Output consistency
- Workflow accuracy
- Task specialization
Fine‑tuning focuses on how the model responds, rather than what external information it retrieves.
Fine‑tuning is best suited for enterprise AI systems that:
- Require consistent tone, structure, or output format
- Perform narrow, well‑defined tasks such as classification or extraction
- Need reduced prompt complexity or lower inference latency
- Operate on stable datasets that do not change frequently
As a result, your AI becomes more specialized and aligned with your business objectives.
How RAG Works in Enterprise AI Systems
At a high level, RAG introduces a retrieval layer between the user query and the model’s response generation. It follows a straightforward workflow. However, behind the scenes, it combines several advanced AI components to deliver accurate and context-aware responses.
Here is how it works conceptually:
- A user query is received by the AI system
- Relevant content is retrieved from approved enterprise data sources
- The retrieved context is injected into the model prompt
- The model generates an answer grounded in that retrieved information
Because the model queries live data sources, knowledge stays current without retraining, which is essential for enterprise environments where information changes frequently.
Core Components of a RAG-Based Enterprise AI System
While implementations vary, most enterprise RAG systems include three foundational components:
- Ingestion layer to prepare and index enterprise data
- Retrieval layer to fetch the most relevant information for each query
- Generation layer where the language model produces grounded responses
Each layer can evolve independently, allowing enterprises to scale, optimise, or swap components without rewriting the entire system.
Key Advantages of RAG in Production AI Systems
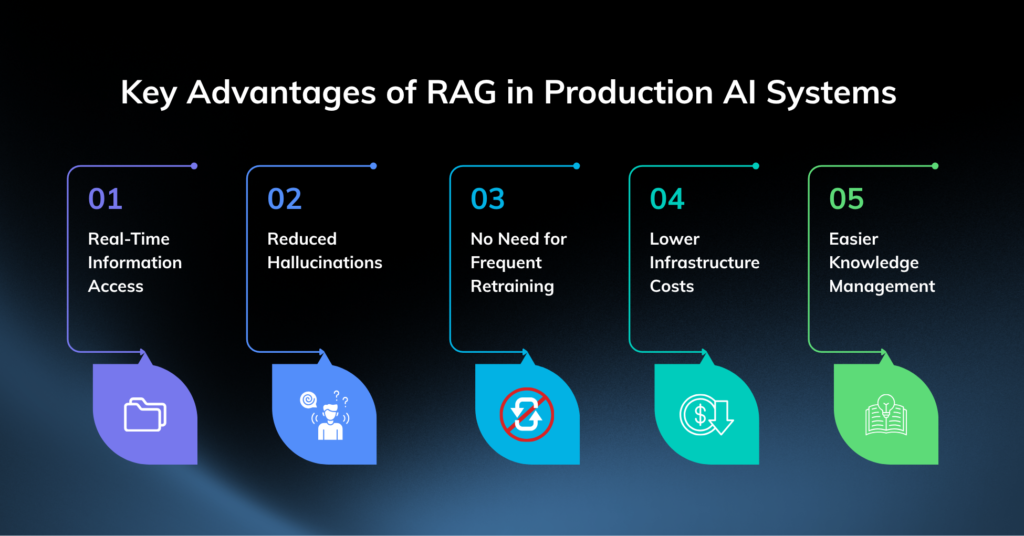
RAG has become one of the most widely adopted enterprise AI architectures because it solves several real-world business problems efficiently.
Here are the biggest advantages.
Real-Time Information Access
Unlike fine-tuned models, RAG systems can access newly added information instantly.
You don’t need to retrain the model every time:
- Policies change
- Documentation updates
- Pricing changes
- New products launch
This makes RAG ideal for dynamic business environments.
Reduced Hallucinations
Hallucinations occur when AI generates inaccurate or fabricated information.
Because RAG grounds responses in retrieved documents, it significantly improves factual accuracy.
The AI is no longer “guessing” from memory alone.
No Need for Frequent Retraining
RAG avoids constant retraining because the knowledge lives outside the model. You simply update your knowledge base.
This dramatically lowers operational overhead.
Lower Infrastructure Costs
RAG systems are often more cost-efficient because they rely primarily on retrieval infrastructure rather than continuous model training.
For many enterprises, this creates a faster and more practical AI adoption path.
Easier Knowledge Management
Your enterprise knowledge remains centralized and manageable.
Instead of embedding proprietary information permanently into model weights, you can:
- Add documents
- Remove outdated files
- Restrict access
- Maintain audit trails
This flexibility is critical for compliance-heavy industries.
How Fine-Tuning Works in Enterprise AI Systems
Fine-tuning involves multiple stages that transform a general-purpose AI model into a domain-specialized enterprise system.
Here’s how the process typically works.
- The first step is gathering high-quality training data.
- Once collected, the data must be structured into training-ready formats.
- Next comes the actual training process.
- After training, the model must be rigorously evaluated.
- Once validated, the fine-tuned model is deployed into production environments.
Types of Fine-Tuning
Not all fine-tuning approaches are the same.
Enterprises now use multiple fine-tuning strategies depending on budget, infrastructure, and performance requirements.
Full Fine-Tuning
Full fine-tuning updates all the model’s parameters during training.
Advantages include:
- Deep behavioral adaptation
- Strong domain specialization
- Maximum performance optimization
Parameter-Efficient Fine-Tuning (PEFT)
Parameter-Efficient Fine-Tuning modifies only a small portion of the model instead of retraining the entire network.
This dramatically reduces:
- Compute costs
- Training time
- Infrastructure requirements
It’s especially useful for organizations that want scalable AI adaptation without massive hardware investments.
LoRA Fine-Tuning
LoRA (Low-Rank Adaptation) is one of the most widely adopted PEFT techniques.
Benefits include:
- Faster training
- Lower memory usage
- Easier deployment
- Reduced infrastructure costs
LoRA has become a practical solution for enterprises building specialized AI systems on limited budgets.
Core Components of a Fine‑Tuned Enterprise AI System
While tooling may vary, most fine‑tuned enterprise AI systems rely on three foundational elements:
- High‑quality training data that reflects the desired behaviour
- Training pipelines to adjust model weights in a controlled manner
- Versioning and governance mechanisms to manage model updates
Because behaviour is learned during training, changes require retraining, which introduces operational trade‑offs that enterprises must account for.
Key Advantages of Fine-Tuning
Fine-tuning offers several powerful advantages for enterprises seeking deeper AI customization.
Deep Domain Specialization
Fine-tuned models can become highly knowledgeable within specific industries. This specialization improves response quality significantly.
Better Tone and Style Consistency
Generic AI models often produce inconsistent communication styles. This is especially valuable for customer-facing AI systems.
Improved Task-Specific Performance
Fine-tuned models often outperform generic models on specialized tasks such as:
- Classification
- Summarization
- Extraction
- Structured output generation
- Workflow automation
Lower Prompt Dependency
Without fine-tuning, enterprises often rely on complex prompts to guide model behavior.
Fine-tuning reduces this dependency because the desired behavior becomes embedded in the model itself.
Reduced Latency in Some Applications
Since the model already “knows” the required behavior, you may not need lengthy retrieval pipelines or massive contextual prompts.
This can improve response speed for certain enterprise applications.
RAG vs Fine‑Tuning: Head‑to‑Head Comparison
While both RAG and fine‑tuning enhance enterprise AI systems, they do so in fundamentally different ways.
The table below compares them across the dimensions that matter most in production environments.
| Dimension | Retrieval‑Augmented Generation (RAG) | Fine‑Tuning |
| Primary Purpose | Provides up‑to‑date, external knowledge at runtime | Embeds behaviour and response patterns into the model |
| Knowledge Handling | Retrieved from external data sources per query | Embedded inside model weights during training |
| Data Freshness | High. Updates do not require retraining | Low to medium. Retraining required for changes |
| Model Weights | Remain unchanged | Modified during training |
| Best Use Cases | Knowledge‑heavy, dynamic, or regulated data | Stable, narrow, and behaviour‑driven tasks |
| Output Consistency | Depends on retrieved context and prompts | Highly consistent and predictable |
| Latency | Slightly higher due to retrieval step | Lower once deployed |
| Operational Complexity | Higher at runtime, easier to update data | Lower at runtime, higher during retraining |
| Compliance & Auditability | Strong. Sources can be traced and controlled externally | Weaker. Knowledge embedded is harder to audit or remove |
| Scalability Across Use Cases | High. Same model can serve multiple domains | Limited. Often task‑ or domain‑specific |
| Cost Over Time | Driven by retrieval and inference usage | Driven by training, retraining, and model management |
Key Takeaway for Enterprise AI Systems
- Use RAG when accuracy depends on what the system knows today
- Use fine‑tuning when reliability depends on how the system responds every time
- Combine both when enterprise scale, governance, and performance must coexist
When RAG Is the Right Choice for Enterprise AI
Retrieval‑Augmented Generation (RAG) is the right choice when an enterprise AI system must stay accurate in the face of constantly changing, proprietary, or regulated information.
Use RAG when:
- Knowledge changes frequently
- Traceability and auditability are required
- Enterprise data must remain isolated
- One AI system serves multiple use cases
When Fine‑Tuning Is the Right Choice for Enterprise AI
Fine‑tuning is the right choice when an enterprise AI system must deliver consistent, predictable behaviour rather than dynamically adapting to changing information. In these scenarios, how the system responds matters more than what external data it consults.
Use fine‑tuning when:
- Behaviour must be consistent
- For narrow, repetitive tasks
- Low latency is critical
- Domain language is stable
Understanding the Cost Structure of RAG and Fine‑Tuning
The decision between RAG and fine‑tuning is not just a technical preference. It is a financial commitment that will shape your cloud spend, infrastructure complexity, and operating costs long after the system goes live.
The Cost Profile of RAG‑Centric Systems
RAG shifts most of its economic burden to runtime operations.
Because relevant documents are injected into the prompt at inference time, each request carries a higher token footprint. As usage scales from thousands to millions of interactions, inference costs can increase sharply, even if model quality remains stable.
In addition to inference spend, RAG systems introduce persistent infrastructure expenses, including:
- Continuous vector database hosting
- Storage and re‑indexing pipelines
- Retrieval monitoring and tuning
These costs do not spike once. They compound steadily over time. RAG architectures offer flexibility and governance benefits, but they do so by accepting higher ongoing operational expenditure tied directly to query volume.
The Cost Profile of Fine‑Tuned Systems
Fine‑tuning follows the opposite financial pattern.
Most costs are incurred before production deployment, not during inference. These include:
- Data preparation and curation
- Specialist engineering or data science effort
- GPU time for model training and evaluation
However, once deployed, fine‑tuned models can be significantly cheaper to run at scale. A properly fine‑tuned open‑source model hosted on enterprise infrastructure can process large workloads with:
- Lower per‑request cost
- Predictable performance characteristics
- Minimal dependency on oversized prompts
This makes fine‑tuning economically attractive for high‑volume, stable workloads, where inference spend dominates total cost over time.
Decision Framework: How to Choose the Right Approach

Now, you already understand what RAG and fine‑tuning are. Let’s decide to choose the right one
Step 1: Identify the Failure Mode
Ask only one question:
When this system fails, is it because the information is wrong or because the response behaviour is wrong?
- Information failure → RAG
- Behaviour failure → Fine‑tuning
If both occur, plan for a hybrid architecture.
Step 2: Evaluate Change Frequency
- Frequent knowledge or policy changes → RAG
- Stable task rules and outputs → Fine‑tuning
- Both change over time → Hybrid
This step determines long‑term maintenance cost more than any other factor.
Step 3: Apply Risk and Governance Constraints
- Need for source‑level auditability or revocable access → RAG or Hybrid
- Controlled outputs with minimal runtime dependencies → Fine‑tuning
Do not optimize for performance before accounting for governance risk.
Step 4: Make the Architectural Call
- Use RAG when correctness depends on what the system knows
- Use Fine‑Tuning when reliability depends on how the system behaves
- Use Both when enterprise scale demands consistent behaviour over changing knowledge
Most enterprise AI systems start with one approach and evolve into a hybrid. The goal is not choosing the “best” technique. The goal is designing a system that fails less often as complexity grows.
Common Mistakes to Avoid
Most enterprise AI failures around RAG and fine‑tuning do not come from poor models. They come from misaligned architectural assumptions made early and left unchallenged.
Treating RAG as a Replacement for System Design
RAG is often added to compensate for weak data foundations or unclear requirements. Without disciplined retrieval scope and governance, it increases cost and complexity without improving reliability.
Overusing Fine‑Tuning to Store Knowledge
Fine‑tuning is frequently misused to “bake in” information that changes over time. This leads to expensive retraining cycles and systems that silently drift out of date.
Optimizing for Accuracy Before Economics
Many teams optimise early demos for response quality while ignoring how costs behave at scale. This results in systems that perform well in pilots but become financially unsustainable in production.
Assuming the First Architecture Will Be the Final One
Enterprise AI systems evolve. Designing for flexibility early is safer than committing fully to a single approach without a path to hybridisation.
RAG or Fine-Tuning: Choosing the Right Approach to Build Smarter Enterprise AI Systems
As enterprise AI adoption accelerates, the debate around RAG vs fine-tuning has become one of the most important architectural decisions businesses must make.
The right architecture depends on:
- How your enterprise knowledge changes
- How predictable system behaviour must be
- How costs scale with usage
- How governance and risk are managed
RAG enables your AI systems to access real-time enterprise knowledge without retraining the model. It excels in environments where information changes frequently and accuracy depends on retrieving the latest data.
Fine-tuning, on the other hand, reshapes the model itself. It helps your AI understand specialized terminology, follow business-specific workflows, maintain consistent communication styles, and perform highly customized tasks with greater precision.
Ultimately, there is no universally “correct” choice between RAG and fine‑tuning. The right choice depends on your organization’s priorities.
Build Your Enterprise AI System with Enlight Lab
At Enlight Lab, we go far beyond basic integrations or thin API layers. We are a premium custom generative AI development services provider, focused on engineering enterprise‑grade AI systems that are secure and scalable.
From architecting large‑scale RAG platforms that index and query vast volumes of internal knowledge, to building fine‑tuned, proprietary models deployed inside isolated VPC environments, our teams handle the full depth of production engineering. We own everything from data pipelines and retrieval architecture to model adaptation, infrastructure, and MLOps, so the system works reliably long after the first deployment.
Ready to build an enterprise AI system that delivers real, measurable value? Consult Enlight Lab team to discuss the right RAG or fine‑tuning architecture for your needs.