Quick answer: Data augmentation in AI models is the process of generating realistic, synthetic data from existing datasets to train machine learning algorithms. It improves AI accuracy by up to 10 percent, reduces overfitting, and provides you with a cost-effective way to overcome data scarcity without manually collecting new raw information.
Building a reliable AI product often feels like an uphill battle. You hire brilliant engineers and design an innovative architecture, only to hit a massive roadblock: you simply do not have enough high-quality data. Manually collecting and labeling thousands of data points requires time and capital that most early-stage companies cannot spare.
This data scarcity leads to models that memorize training data instead of learning underlying patterns. When deployed to real users, these constrained models fail to handle unexpected edge cases, resulting in poor user experiences and lost revenue.
Fortunately, you do not need to spend your entire runway buying datasets. Implementing data augmentation in your AI model development solves this problem by artificially expanding the variety and volume of your existing data. By applying strategic transformations to the information you already have, your engineering team can build resilient systems that perform exceptionally well in the real world.
This guide breaks down exactly how these techniques work, the proven impact on performance, and the steps you must take to implement them effectively.
What Data Augmentation in AI Models Is
Data augmentation is a systematic approach to creating new training examples by modifying existing data or generating synthetic data from scratch. Instead of sending teams out to gather thousands of new audio clips or medical scans, your engineers can use algorithms to alter current files.
And Why You Need It
For a startup competing against enterprise giants, this approach is the great equalizer. It allows smaller teams to train highly sophisticated systems on limited budgets. Data augmentation has become a standard practice in modern machine learning training pipelines, especially in computer vision and deep learning applications.
When you use data augmentation effectively, you can:
- Build AI models with less data
- Reduce development and operational costs
- Launch AI products faster
- Improve product accuracy and user experience
The primary goal is to teach your neural network that a specific object or concept remains the same even when its environment changes. When a model learns to recognize an object across multiple synthetic variations, it develops a deeper, more generalized understanding of the core features.
When Should You Use Data Augmentation?
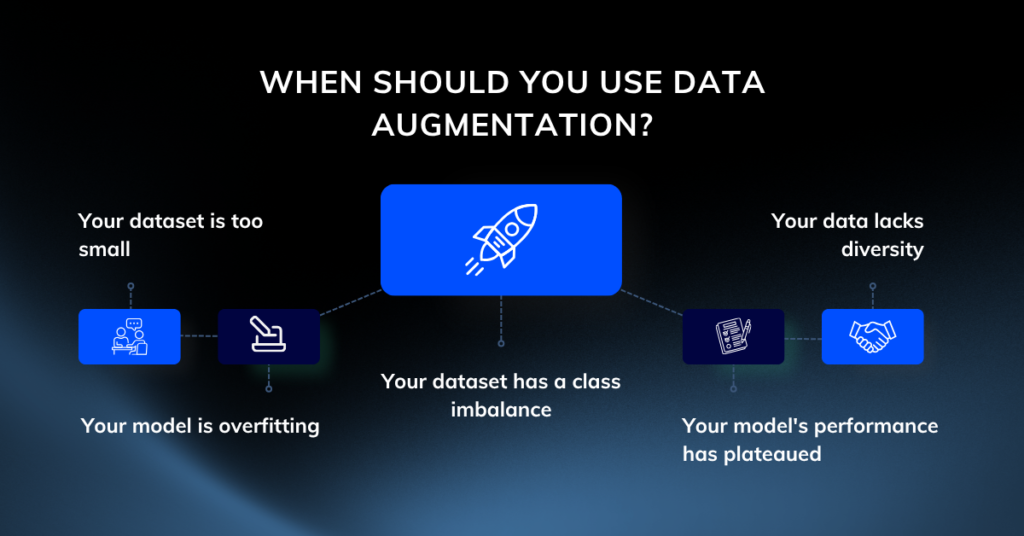
Data augmentation can be a powerful tool when your model’s performance is not meeting expectations. Here’s when you should consider using it:
- Your dataset is too small: If you have a limited number of samples, your model may not have enough data to learn effectively. Augmentation creates more training examples without the need for new data collection.
- Your model is overfitting: A key sign of overfitting is high accuracy on your training data but poor performance on validation or test data. Augmentation introduces variability, helping the model generalize better to unseen data.
- Your dataset has a class imbalance: If some classes are underrepresented, the model may struggle to learn their features. Augmenting these minority classes helps balance the dataset and improve fairness.
- Your model’s performance has plateaued: If you’ve tuned your hyperparameters and the model’s performance metrics are no longer improving, augmenting the data can introduce new variations and unlock better results.
- Your data lacks diversity: If a visual inspection reveals limited variations in lighting, orientation, scale, or backgrounds, augmentation can fill these gaps and make your model more robust.
Top Techniques for Data Augmentation in AI Models
Different data modalities require entirely different transformation strategies. Here is a breakdown of the standard techniques your engineers can use across various formats.
Augmenting Image Data
Computer vision relies heavily on geometric and color transformations. Engineers apply modifications that mimic how a human eye might view an object from different angles or in different lighting conditions.
- Geometric transformations: These include random cropping, horizontal or vertical flipping, and rotation.
- Color manipulation: Adjusting brightness, contrast, hue, and saturation introduces necessary variations.
- Advanced mixing: Techniques like CutMix involve cutting and pasting patches from one image into another, forcing the system to recognize partial features.
Best Methods for Text Data Augmentation
Natural Language Processing (NLP) tasks pose a unique challenge because altering a single word can completely change a sentence’s meaning.
- Synonym replacement: Algorithms replace specific words with their closest synonyms using databases like WordNet.
- Back-translation: A script translates an English sentence into French, and then translates it back to English. This preserves the original semantic meaning while introducing fresh syntactic structures.
- LLM generation: Frameworks like AugGPT leverage large language models to rewrite and paraphrase sentences at scale.
Expanding Audio Datasets
Speech recognition and audio classification systems must operate in noisy, unpredictable environments.
- Noise injection: Adding background static, street noise, or room echo simulates real-world conditions.
- Pitch shifting: Altering the pitch of an audio clip simulates different speakers, genders, and accents.
- Time stretching: Speeding up or slowing down the playback helps the algorithm understand speech regardless of how fast a person talks.
Augmenting Tabular and Financial Data
Tabular data—the kind you find in Excel spreadsheets and SQL databases requires statistical precision.
- SMOTE (Synthetic Minority Over-sampling Technique): This technique addresses class imbalance by interpolating new data points between existing minority class examples.
- Feature corruption: Frameworks like VIME use table masking to intentionally corrupt features, forcing the model to reconstruct the missing information.
- Autoencoders and GANs: Generative Adversarial Networks (GANs) create entirely new rows of synthetic data that mimic real data by learning patterns from existing datasets, enabling them to generate realistic samples for AI training and testing.
How Data Augmentation Improves AI Model Accuracy
You may be asking exactly how tweaking existing data translates to a smarter algorithm. The improvements stem from three foundational changes to the learning process.
Reducing Critical Overfitting Errors
Overfitting occurs when a machine learning model learns the training data too well, capturing the noise and anomalies rather than the actual signal. When you introduce augmented variations, you prevent the algorithm from memorizing specific data points. According to a comprehensive survey on data augmentation for NLP, these techniques reduce overfitting by 20% to 30%, resulting in a much more reliable product.
Increasing Training Data Diversity
Real-world environments are chaotic. An autonomous vehicle will encounter stop signs covered in snow, obscured by tree branches, or faded by the sun. By synthetically generating these specific visual impairments during the training phase, the model learns to identify the core geometry of the stop sign regardless of the visual noise.
Handling Rare Cases and Imbalanced Datasets
In industries like healthcare and finance, critical events like a rare tumor or a fraudulent transaction happen infrequently. A dataset might contain 99,000 normal transactions and only 1,000 fraudulent ones. Without intervention, the algorithm will simply learn to predict “normal” every time. Augmentation artificially multiplies those 1,000 rare cases, forcing the system to accurately identify the specific markers of fraud.
The Real-World Impact of Data Augmentation on Model Performance
The theoretical benefits of data augmentation translate into measurable, bottom-line performance gains across multiple industries.
Healthcare Diagnostics and Medical Imaging
Acquiring labeled medical data is notoriously difficult due to strict privacy laws like HIPAA. Multiple medical AI studies have shown that data augmentation improves medical image classification performance, particularly when training data for rare diseases is limited.
Financial Services and Fraud Detection
Banks process millions of transactions daily, but catching the few fraudulent ones requires incredibly sensitive algorithms. Financial institutions increasingly use synthetic transaction data to improve fraud detection systems. Studies and industry research show that augmenting fraud datasets can improve model accuracy, reduce false negatives, and strengthen anomaly detection performance.
Natural Language Processing and Chatbots
Generative AI and customer service chatbots rely heavily on diverse conversational data. Research shows that text data augmentation techniques such as synonym replacement and noise injection can improve NLP model performance by 5% to 15%, with some studies reporting gains of up to 30% depending on the use case and dataset.
Best Practices for Implementing Data Augmentation
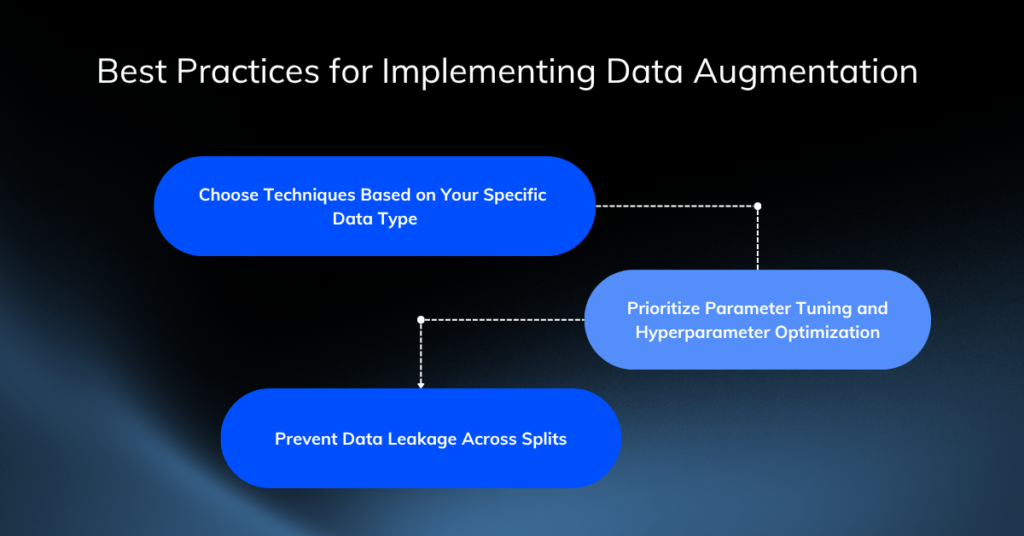
Adding noise to your data randomly will not yield results. You should enforce the following best practices within your engineering teams.
Choose Techniques Based on Your Specific Data Type
Choose simple transformations like random cropping if computational efficiency matters more than complex feature generation. Choose GAN-based synthetic data generation if you operate in a highly regulated industry (like healthcare) where preserving patient privacy is more important than fast training times.
Prioritize Parameter Tuning and Hyperparameter Optimization
Excessive augmentation destroys the original signal. If you rotate a picture of a number “9” too far, it becomes a “6”, fundamentally corrupting your dataset. Your engineering teams must experiment with augmentation intensity and use cross-validation to ensure the transformations maintain semantic integrity.
Prevent Data Leakage Across Splits
Data leakage ruins model credibility. If an original image is placed in the training set, but its augmented, cropped version accidentally ends up in the testing set, the model will score artificially high. Always split your dataset into training, validation, and testing sets before applying any augmentation algorithms.
Computational Challenges and Limitations
While highly effective, you must understand the associated costs and technical hurdles before scaling these operations.
Managing Computational Costs
Generating thousands of synthetic images or translating millions of text rows requires significant compute power. Cloud GPU costs can spiral out of control if augmentation pipelines are not optimized.
You should apply augmentations dynamically on the fly during training batches, rather than pre-generating and storing massive hard-copies of augmented datasets.
Avoiding Artificial Artifacts
When using generative models to create data, the system may introduce subtle digital artifacts. A medical AI trained on synthetic X-rays might learn to identify the digital noise created by the GAN, rather than the actual markers of a disease.
Regular quality audits are mandatory.
Data Augmentation vs No Augmentation: Comparison Table
When you’re building AI models, the difference between using data augmentation and skipping it directly impacts how your product performs, how fast you scale, and how reliably your AI works in real-world scenarios.
Below is a comparison highlighting the key differences between using data augmentation and not employing it in a machine learning pipeline:
Data Augmentation vs No Augmentation
| Factor | Without Data Augmentation | With Data Augmentation |
| Dataset Size & Diversity | Limited and narrow dataset | Expanded dataset with multiple variations |
| Model Accuracy | Moderate; struggles with unseen data | Higher accuracy due to better pattern learning |
| Generalization Ability | Low; fails in real-world scenarios | Strong; adapts to new inputs effectively |
| Overfitting Risk | High; model memorizes training data | Reduced; learns general features instead of memorising |
| Development Cost | Higher due to need for more data collection | Lower; maximises existing data efficiently |
| Time to Market | Slower due to data dependency | Faster iteration and quicker model training |
| Model Robustness | Fragile; sensitive to slight variations | More robust to real-world noise and variability |
| Scalability | Hard to scale without large datasets | Easier to scale even with limited data |
| Data Privacy Handling | Depends on raw data usage | Safer with transformed or synthetic variations |
Future Trends in Data Augmentation for 2026
As the artificial intelligence landscape matures, the methods we use to train systems are becoming autonomous. You should prepare for these upcoming shifts.
Meta-learning and AutoAugment Policies
Instead of having a human data scientist guess which transformations will work best, engineers now use reinforcement learning agents to discover the optimal augmentation strategy. The AutoAugment framework automatically searches for the best combination of transformations for a specific dataset, reliably improving image classification accuracy by 3% to 5% over manual methods.
Advanced GANs and Diffusion Models
Generative AI foundation models are stepping in to augment data for smaller, specialized models. Tools like Stable Diffusion can now edit existing images with impressive flexibility. Businesses use them to change backgrounds, adjust lighting, and create realistic training data for industries like autonomous vehicles and retail analytics.
How Enlight Lab Helps Build Better AI Training Datasets
Building an effective data augmentation pipeline requires a deep understanding of your data, your model behaviour, and the real-world conditions your AI will face.
At Enlight Lab, we treat data augmentation as a core part of your AI development strategy, not just a preprocessing step.
We start by analyzing your dataset at a granular level, identifying gaps, biases, and performance bottlenecks. Based on this, our AI engineers design augmentation strategies that preserve label integrity while introducing the right level of variability. Every transformation we apply is intentional, tested, and aligned with your specific business use case.
Most importantly, we validate every step to ensure that augmentation actually improves model generalization, not just training metrics.
Our AI development services cover the full lifecycle:
- Data quality diagnostics to uncover hidden limitations in your dataset
- Tailored augmentation strategy aligned with your use case
- Pipeline implementation integrated into your ML workflows
- Continuous performance monitoring to track real-world accuracy and reliability
If your datasets have deeper structural issues, we help you identify and fix them early before they impact downstream model performance.
And if you’re running AI workloads across cloud environments, we design flexible pipelines that integrate seamlessly into your existing stack.
You get AI systems that are more accurate, more reliable, and easier to scale built on a smarter data foundation.
Ready to Scale Your Data Augmentation in AI Model Strategy?
A sophisticated data augmentation strategy is the fastest, most capital-efficient way to move your product from a brittle prototype to a robust, enterprise-ready solution. By systematically addressing overfitting, multiplying rare edge cases, and simulating real-world chaos, you empower your neural networks to make highly accurate predictions.
If you’re building an AI product and want to:
- Improve model accuracy without increasing costs
- Reduce time-to-market for your AI solutions
- Scale your product with confidence
Then it’s time to move beyond experimentation. The right data strategy can unlock your next stage of growth.
Connect with Enlight Lab today to turn limited data into high-performance AI systems without hassle.
Frequently Asked Questions (FAQ)
What is the primary benefit of data augmentation for a startup?
Data augmentation allows you to train highly accurate machine learning models without the prohibitive cost and time delays associated with manually collecting and labeling massive amounts of real-world data.
How much does data augmentation actually improve AI accuracy?
Depending on the domain, data augmentation consistently delivers measurable gains. Studies indicate a 10% accuracy increase in medical image classification, an 8% improvement in financial fraud detection, and a 5% to 10% performance boost in natural language processing tasks.
Are there risks associated with augmenting training data?
Yes. If applied incorrectly, data augmentation can introduce digital artifacts, alter the core meaning of the data (such as flipping a “9” into a “6”), or cause data leakage between training and testing sets, resulting in falsely inflated performance metrics.
Should I use manual augmentations or generative AI (GANs) for my data?
Use manual augmentations (like image cropping or text synonym replacement) for rapid, cost-effective model improvements. Choose generative AI or GANs when you need to synthesize entirely new examples for complex edge cases or when you must preserve user privacy in sensitive tabular datasets.
What is AutoAugment?
AutoAugment is an advanced meta-learning technique that uses reinforcement learning algorithms to automatically search through thousands of possible data augmentation policies to find the exact combination that maximizes model performance for a specific dataset.