Every IT team has been there. It’s 2 a.m. A critical application goes down. Alerts flood in from six different monitoring tools. Engineers scramble to sift through thousands of log lines, chasing the source of an outage that’s costing thousands of dollars per minute.
This isn’t a failure of talent. It’s a failure of tools built for a simpler era.
Modern IT environments are sprawling, dynamic, and brutally complex. Microservices, hybrid cloud architectures, containerized workloads, and continuous deployment pipelines generate more operational data than any human team can realistically process. Traditional monitoring tools, built for static infrastructure, simply weren’t designed for this level of complexity.
That’s where AIOps enters. Not as a buzzword, but as a practical, measurable answer to one of the most pressing challenges facing engineering and IT teams today.
This guide breaks down what AIOps is, how it works, what it delivers, and why it’s quickly shifting from a competitive advantage to a baseline expectation for serious technology organizations.
The Evolution of IT Operations: From Manual Firefighting to Intelligent Automation
To understand why AIOps matters, it helps to trace how IT operations got here.
The Era of Manual IT Management
For decades, IT operations teams worked reactively. Infrastructure was mostly static. On-premises servers ran predictable workloads. When something broke, engineers reviewed logs, checked dashboards, and eventually pieced together what happened.
This approach worked, but it was slow, expensive, and deeply reliant on individual expertise. Institutional knowledge lived in people’s heads, not in systems.
The Cloud Complexity Problem
The shift to cloud computing changed everything. Organizations gained agility and scalability, but they also inherited exponential complexity. Applications now depend on dozens of interconnected services. A single performance issue can cascade across multiple systems, affecting customers before any alert fires.
Monitoring tools multiplied to keep up. Teams today typically manage five or more separate tools, each generating its own stream of alerts.
The result: alert fatigue, longer resolution times, and teams spending more time managing tools than managing outcomes.
Why AI in IT Operations Changes the Equation
AI in IT operations does what humans simply cannot do at scale.
- It ingests and correlates massive volumes of data in real time.
- It learns from historical patterns to detect anomalies before they escalate.
- It identifies root causes across complex, multi-layered environments in seconds, not hours.
This shift, from reactive firefighting to proactive intelligence, is the core promise of AIOps. With expert DevOps consulting services, you can successfully integrate these capabilities into your systems, overcome the limitations of traditional monitoring tools, and build more intelligent, resilient IT operations.
What Is AIOps? A Clear Definition
AIOps, short for Artificial Intelligence for IT Operations, is the application of AI capabilities, including machine learning, natural language processing, and predictive analytics, to automate, streamline, and optimize IT service management and operational workflows.
The term was coined by Gartner, which defines AIOps platforms as systems that analyze telemetry and event streams to transform data into meaningful patterns and enable proactive responses that reduce operational toil and overhead.
AIOps platforms do three things well:
- Aggregate operational data from across the IT environment, including logs, metrics, traces, events, and ticketing systems
- Analyze that data using machine learning to surface the signals that actually matter
- Act on those signals, either by routing them to the right team or by automatically resolving the issue without human intervention
AIOps is not a single tool. It’s a category of platform that unifies observability, intelligence, and automation into one continuous operational loop.
Key Components of AIOps: What Powers the Platform
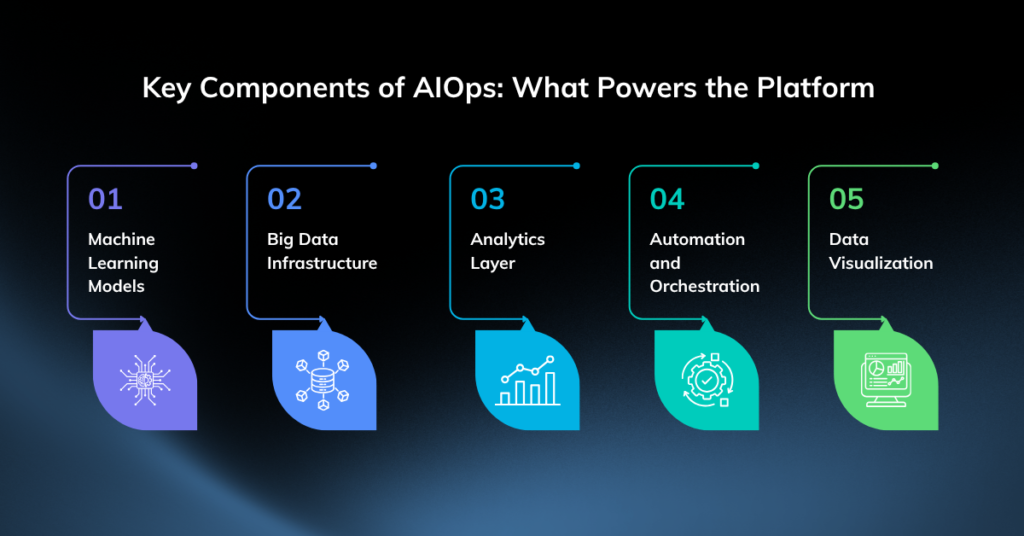
Understanding AIOps means understanding the technologies underneath it. These are the building blocks that make the platform intelligent.
Machine Learning Models
Machine learning is the analytical engine of AIOps. It enables platforms to establish baseline behavior for every system and service, then detect deviations from that baseline with precision.
ML techniques used in AIOps include supervised learning, unsupervised learning, reinforcement learning, and deep learning, each suited to different types of operational problems.
Big Data Infrastructure
AIOps platforms must ingest and process enormous volumes of data, often in real time. This requires purpose-built data infrastructure capable of handling the following data types simultaneously:
- Historical performance data
- Real-time event streams
- System logs and metrics
- Network packet data
- Incident tickets
- Application demand signals
Analytics Layer
Raw data alone is not useful. The analytics layer interprets that data, identifies trends, isolates anomalies, forecasts capacity demands, and correlates events across different parts of the environment. This is where patterns become actionable insights.
Automation and Orchestration
Automation is what converts AIOps insights into outcomes. When the platform detects an anomaly and identifies the root cause, automation workflows can trigger a response, whether that’s reallocating compute resources, restarting a service, or escalating to the right engineer with full context already assembled.
Data Visualization
Even the most sophisticated AI platform needs to communicate with humans. Dashboards, topology maps, and real-time visualizations translate complex operational data into formats that teams can act on quickly.
How AIOps Transforms IT Operations
This is where the real impact lives. AIOps doesn’t just improve existing processes. It fundamentally changes how IT teams operate.
Predictive Analytics: Solving Problems Before They Happen
Traditional monitoring tells you when something has gone wrong. Predictive analytics tells you when something is about to go wrong.
AIOps platforms continuously analyze performance data and apply forecasting models to identify patterns that precede IT incidents. If historical data shows that a specific combination of memory usage and network latency reliably precedes a service outage, the platform flags and addresses that combination before any user is affected.
According to Forbes, AIOps is evolving from a reactive IT operations model toward a proactive approach capable of predicting and resolving issues before they escalate. For engineering teams under pressure to maintain uptime commitments, this shift is significant.
Anomaly Detection: Finding the Signal in the Noise
Modern IT environments generate enormous volumes of alerts. Most are noise. A few represent genuine threats to performance or availability.
AIOps tools apply machine learning to distinguish between the two. By learning what normal looks like across thousands of metrics, the platform flags genuinely atypical behavior and filters out everything else. This directly addresses alert fatigue, one of the most common and costly problems in IT operations today.
Root Cause Analysis: From Symptom to Source
When a distributed system misbehaves, finding the root cause is like untangling a web with hundreds of threads. A slowdown in one service might trace back to a database query, a network misconfiguration, or a recently deployed code change three layers removed.
AIOps accelerates root cause analysis by correlating events across the entire environment. Rather than engineers manually tracing dependencies, the platform maps relationships, evaluates correlated anomalies, and surfaces the most probable cause with supporting evidence. This can reduce mean time to repair (MTTR) from hours to minutes.
Automated Remediation: Closing the Loop Without Human Delay
Not every incident requires a human decision. Many operational issues, service restarts, resource reallocation, configuration rollbacks, follow predictable remediation patterns. AIOps platforms can execute these responses automatically, acting on ML insights the moment an issue is confirmed.
AI in DevOps automation is becoming particularly powerful here. When AIOps is integrated into CI/CD pipelines, it can detect performance regressions introduced by a new deployment and trigger an automatic rollback before the change reaches production.
When AIOps is integrated into CI/CD workflows, it can detect performance regressions from new deployments and trigger automatic rollbacks before changes reach production. This enables more intelligent and reliable AI-Powered CI/CD Pipelines.
Benefits of AIOps: What Organizations Actually Gain
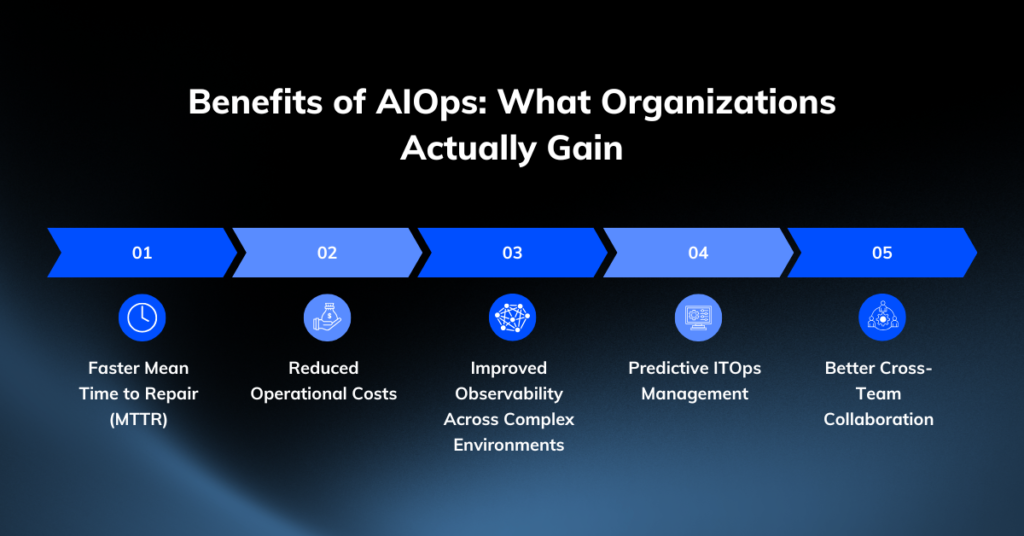
The business case for AIOps is grounded in measurable outcomes.
Faster Mean Time to Repair (MTTR)
By cutting through alert noise and correlating data across environments, AIOps identifies root causes faster than any manual process. Faster identification means faster resolution, which means less downtime and lower incident costs.
Reduced Operational Costs
Automation reduces the manual overhead associated with routine IT tasks. Engineers spend less time on alert triage and repetitive incident response, and more time on work that drives business value. That’s not just efficiency, it’s also a meaningful improvement in employee experience and retention.
Improved Observability Across Complex Environments
AIOps provides end-to-end visibility across hybrid and multi-cloud environments, including dependencies that are too dynamic to document manually. IBM describes this capability as bridging the gap between diverse, difficult-to-monitor IT landscapes and user expectations of application performance.
Predictive ITOps Management
With continuous learning built in, AIOps platforms get smarter over time. They adapt to changes in the environment, from new infrastructure provisioned by DevOps teams to seasonal shifts in application demand, and adjust their baseline models accordingly.
Better Cross-Team Collaboration
AIOps platforms create a shared operational picture. Rather than siloed teams working from different tools and datasets, DevOps, ITOps, security, and governance teams can work from the same intelligence, improving coordination and accelerating resolution.
Use Cases of AIOps Across the Enterprise
AIOps is not limited to a single domain. The platform applies across multiple operational contexts.
Network Performance Monitoring
AIOps monitors network traffic, latency, packet loss, and configuration changes in real time. When behavior deviates from baseline, the platform identifies whether the cause is a security threat, a misconfiguration, or a capacity issue, and routes the appropriate response.
Application Performance Management
Application performance management is one of the most mature AIOps use cases. Platforms monitor user experience, backend response times, database query performance, and service dependencies, correlating signals across the entire application stack to maintain performance under varying load conditions.
Cloud Migration and Hybrid Environment Management
Most organizations adopt cloud gradually, creating hybrid environments with complex interdependencies. AIOps provides the visibility needed to manage these environments safely, reducing the operational risk associated with migration and enabling teams to maintain service continuity throughout the transition.
Security and Anomaly Response
AIOps tools support security operations by detecting unusual access patterns, data exfiltration signals, and other behavioral anomalies that may indicate a breach or insider threat. Early detection reduces the potential blast radius of security incidents.
Challenges and Considerations When Implementing AIOps
AIOps delivers real value, but implementation is not without friction. Understanding the challenges upfront leads to better outcomes.
Data Quality and Coverage
AIOps platforms are only as intelligent as the data they ingest. Incomplete telemetry, inconsistent log formats, and siloed data sources can limit the platform’s ability to correlate events accurately. A successful AIOps implementation starts with a data strategy.
Integration Complexity
Most organizations have existing monitoring tools, ticketing systems, and cloud platforms that must be integrated into the AIOps environment. This integration work is not trivial and requires careful planning to avoid gaps in visibility.
Skill Gaps
AIOps platforms require teams who understand both the technology and the operational context. Training IT staff to interpret AI-generated insights, validate model outputs, and configure automation workflows is an ongoing investment, not a one-time effort.
Model Transparency and Accountability
Trusting an AI model to make operational decisions requires confidence in how that model reaches its conclusions. Organizations should prioritize platforms that offer explainable AI outputs and maintain human oversight for high-stakes decisions. IBM recommends assigning a human to validate AI model conclusions and ensure system accountability.
The Future of AIOps: What’s Next
The AIOps market is growing rapidly. According to IMARC Group, the global AIOps market was valued at USD 32.5 billion in 2025 and is projected to reach USD 132.2 billion by 2034, growing at a CAGR of 16.9%.
Several developments are accelerating that trajectory.
Agentic AI and Autonomous Operations
The next generation of AIOps platforms is incorporating agentic AI, systems that don’t just detect and recommend but autonomously execute multi-step remediation workflows. Dynatrace’s 2026 research on agentic AI signals a shift toward fully autonomous IT operations where AI agents handle prevention, remediation, and optimization at scale with minimal human intervention.
Large Language Models in IT Operations
Large language models are being applied to IT operations to make sense of unstructured data, such as incident reports, runbooks, and support tickets. LLMs can surface relevant historical context during an active incident, dramatically accelerating the resolution process for human engineers.
Deeper DevOps and Platform Engineering Integration
The boundary between AIOps and DevOps is narrowing. As platforms mature, AI-driven observability is becoming embedded directly into development workflows, enabling teams to catch issues earlier in the software lifecycle, at build and test time, rather than after deployment.
Causal AI for Precise Diagnostics
Beyond correlation-based anomaly detection, causal AI determines not just what happened but why. By modeling causal relationships between system components, these approaches deliver root cause analysis with greater precision and fewer false positives.
AIOps Is No Longer Optional for Modern IT
IT environments are not getting simpler. The pace of deployment is accelerating. The infrastructure is growing more distributed. User expectations for availability and performance have never been higher.
Manual approaches to IT operations, however skilled the teams executing them, are structurally insufficient for this environment. The data volume is too large, the dependencies too complex, and the pace of change too fast.
AIOps gives IT and engineering teams a way to stay ahead of that complexity rather than constantly catching up to it. It shifts the operational model from reactive incident management to proactive, intelligent automation, with measurable impact on uptime, cost, and team efficiency.
The organizations implementing AIOps now are building operational resilience that compounds over time. The AI models get smarter. The automation workflows get more precise. The teams get faster.
The question is not whether your organization needs AIOps. The question is how quickly you can build the foundation to implement it well.
Start by auditing your current observability coverage. Identify where data silos exist. Map your highest-frequency incident types. Then evaluate which AIOps capabilities address your most costly operational pain points first. The path to intelligent IT operations starts with understanding exactly where the gaps are today.
Take the first step toward intelligent IT operations today. Partner with Enlight Lab to unlock scalable AIOps solutions that reduce operational costs, eliminate data silos, and accelerate your team’s efficiency. Contact us now to start building your foundation for success!